Clique aqui para assistir o vídeo da aula online do dia 14 de maio de 2021. E o chat.
Unidades de Análise
A maioria de projetos exigem a combinação de dados de fontes diversas. É assim que criamos a nossa própria contribuição para a pesquisa. Por exemplo, para estudar o efeito de um programa de governo sobre a votação, preciseramos de pelo menos dois bancos de dados, um com os dados da localização do programa e outro sobre os resultados eleitorais. Como podemos juntar estes dois bancos para facilitar a nossa análise?
Primeiro, temos que entender os dois bancos:
(i) qual é a unidade de análise de cada observaçao?; (ii) quais são os identificadores únicos (as variáveis ‘chaves’) em cada banco que identificam unicamente cada observação (evitando duplicações)?; (iii) quais são os identificadores comuns presentes em ambos os bancos que permitem cruzar as informações?
No exemplo acima, pode ser que o programa do governo foi executado em alguns municípios e não em outros, então o nosso banco varia por município, identificado unicamente com a variável do código municipal do IBGE. Por outro lado, imagine que temos os dados eleitorais resumidos por cada município com o a margem de vitória, então a unidade de análise é cada município, identificado pelo código municipal do IBGE também.
Quando os nossos dois bancos têm a mesma unidade de análise (o municipio) e o mesmo identificador único (código IBGE), o indentificador comum é óbvio: é o código IBGE. Assim, a junção dos bancos é mais ou menos fácil - usamos as variáveis de identificador único e comum (código IBGE) para cruzar as informações e adicionar as colunas de um banco para o outro.
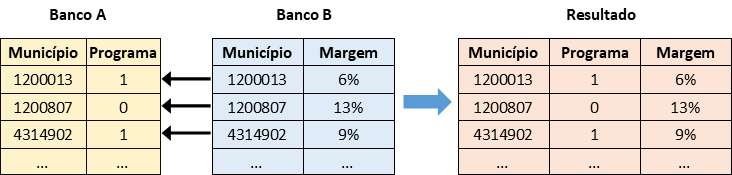
Isto é a circunstância mais fácil para cruzar os dois bancos: a mesma unidade de análise, um identificador único e comum em cada banco, e dados completos.
Unidades Diferentes
Imagine agora que o banco de dados do programa do governo varia por estado em vez do município, então ele tem apenas 27 observações, identificadas por sigla do estado (“AC” etc.). Neste caso em que a unidade de análise e as variáveis variam entre bancos, como é possível juntar os bancos? Primeiro, temos que decidir a unidade de análise desejada do banco de dados final - por estado ou por município? As duas são possíveis.
Estratégia 1 (por estado): Agregando o banco com mais unidades: Se quissemos uma tabela final por estado, temos que agregar os dados eleitorais do nível municipal para o nível estadual com as ferramentas já conhecidas (%>% group_by(Estado) %>% summarize()). Isto exige uma decisão sobre como a agregar cada variável municipal para o estadual - a média, a soma, a mediana, o mínimo etc. Com os dois bancos no nível estadual, é fácil executar a junção, e o resultado será um banco de dados com dados eleitorais e do programa por cada estado.

Estratégia 2 (por município): Duplicando os dados do banco com menos unidades: Se quissemos uma tabela final por município, temos que reconhecer que juntando os dois bancos vai duplicar os dados estaduais para cada município no estado. Por exemplo, a presença do programa indicado por código ‘1’ em “AC” será reptido para cada município de Acre. Isto faz sentido neste contexto, mas é crucial entender se o programa realmente foi executado assim.
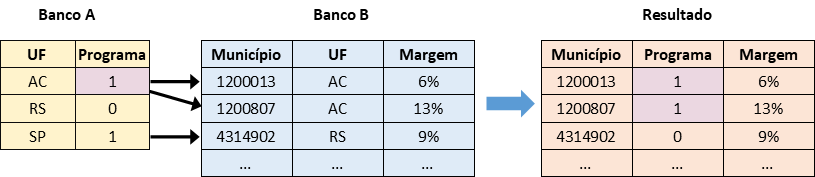
Porém, existe uma outra dificuldade com qualquer uma das duas estratégias - o identificador único de estados (“AC”) não é ígual ao identificador único dos municípios (“1200013”). Como o R vai saber como a cruzar observações de um banco com o outro? Ele precisa saber em qual estado fica cada município. Então nós temos que encontrar um jeito de adicionar uma nova coluna que indica o estado no Banco eleitoral (Banco B) para facilitar o cruzamento. Em termos gerais, precisamos de um identificador comum nos dois bancos.
Pode ser que os dados do estado de cada município já existem no banco, ou pode ser necessário fazer outro cruzamento para importá-los. Em nosso exemplo, a informação do estado está presente nos dois primeiros digitos do código de município, e podemos criar o identificador comum: Temos que separar os primeiros dois dígitos do código municipal que indicam o estado, e depois mapear os dígitos para a sigla. O resultado será uma nova variável, a sigla do estado, para cada município. Agora, temos a sigla do estado no mesmo formato nos dois banco de dados e eles são compatíveis para cruzar. Apenas no final dessa preparação é possível juntar os dois bancos.
Exemplos de Joins Simples (left_join)
Até agora, só discutimos os passos preparatórios:
(1) Decidir a unidade de análise do banco de dados final,
(2) Se necessário, agregar os bancos de dados iniciais para a unidade de análise desejado,
(3) Transformar as variáveis para que temos um identificador comum entre os banco de dados.
O próximo passo é juntar os dois bancos. Vamos usar a função left_join(). Temos que definir três argumentos: Os nomes dos dois bancos de dados, e o conjunto de variáveis que compõem o identificador comum (a ‘chave’) que usaremos para realizar a junção. O R vai combinar as colunas das observações com o mesmo valor de identificador comum nos dois bancos e insira-as como uma linha na nova tabela.
Sempre começamos com o banco de dados que já tem a unidade de análise e número de linhas desejadas no banco de dados final, e encaminhamos este banco para a função left_join(). Dentro de left_join especificamos o segundo banco de dados, e a variável (ou as variáveis num vetor) do identificador comum.
Banco_1 %>% left_join(Banco_2, "Identificador Comum")
Para praticar, vamos abrir um outro banco de dados no pacote nycflights13, esta vez sobre os aviões mesmo, planes. A unidade de flights é um voo (uma partida de Nova Iorque) e à unidade de planes é um avião, que obviamente pode aparecer várias vezes em flights. A variável de identificar comum é tailnum, que é exclusivo para cada avião.
Para ver um exemplo de cruzamento em que a unidade de análise é basicamente ígual - cada avião faz uma viagem só - vamos filtrar os voos para um dia e trajeto específico.
flights_JFK_ATL <- flights %>% filter(month==4 & day==22 & origin=="JFK" & dest=="ATL")
Pode verificar que os cinco aviões (o tailnum) só aparecem uma vez na tabela acima. Agora, é fácil cruzar as duas tabelas com o identificador único e comum:
flights_JFK_ATL %>% left_join(planes, by="tailnum")
Explore a tabela. O resultado é como previsto: uma linha para cada voo, com os dados da avião nas colunas finais, mais para a direita. Simples.
Observe que o pacote tidylog é de grande valor aqui. Ele resume os detalhes do join e imprimi-los no console. Assim, você pode verificar quantas observações existem nos dois bancos (‘matched rows’) e se haver dados faltantes no primeiro banco de dados (‘rows only in y’) e no segundo banco de dados (‘rows only in x’).
Mais geralmente, se nós não filtramos os voos anteriormente e temos aviões duplicados, temos que planejar com mais cuidado: Qual unidade de análise queremos na tabela final? Uma linha por voo, ou uma linha por avião?
Estratégia 1: Agregando o banco com mais unidades: Uma opção é por avião, resumindo por exemplo o número de viagens de cada avião, que exige uma agregação do banco flights por tailnum:
Observe que flights_por_aviao tem muito menos observações que flights, e a unidade de análise é cada avião, compatível com a unidade da tabela planes. Agora ,a junção é fácil, agora começando com planes:
planes_com_num_viagens <- planes %>% left_join(flights_por_aviao, by="tailnum")
Como aparece o resultado final? O planes agora tem mais uma coluna, n, com o número de viagens de cada avião - poderoso, né? Note que o número de linhas no resultado é ígual ao número de linhas no banco de planes.
Estratégia 2: Duplicando os dados do banco com menos unidades: A outra opção é gerar um novo tibble com cada observação um voo, e adicionando dados da avião ao tabela de flights. Dado que temos múltiplos voos para cada avião isso implica uma duplicação dos dados de avião cada vez que ele aparece no banco flights.
flights_com_planes <- flights %>% left_join(planes, by="tailnum")
Observe que flights_com_planes tem o mesmo número de linhas que flights. Vamos filtrar e ordenar os nossos dados para ver que os dados do avião são repetidas cada vez que o avião fez uma viagem (por exemplo avião N11109 aparece quartro vezes):
Observe que geramos um problema pequeno quando juntamos os dois bancos: ambos os bancos originais contém uma variável se chama ‘year’. Dado que as variáveis têm que ter nomes únicos, o R renomeou as colunas ‘year.x’ e ‘year.y’. Isto é um pouco chato porque realmente não distingue informação diferente: o ano da viagem (year.x) e o ano da fabricação do voo (year.y). É sempre melhor renomear as variáveis antes da junção para evitar conflitos e descrever melhor as nossas variáveis, ou selecionar apenas as variáveis que você quer transportar de um banco de dados para o outro:
Agora, o nosso novo tibble, produto da junção, é pronto para analisar e visualizar como qualquer outro tibble que já vimos. Por exemplo, vamos resumir o número de voos por ano de fabricaçao da avião:
flights_com_planes %>%
group_by(year_fabricação) %>%
tally() %>%
ggplot() +
geom_col(aes(x=year_fabricação, y=n))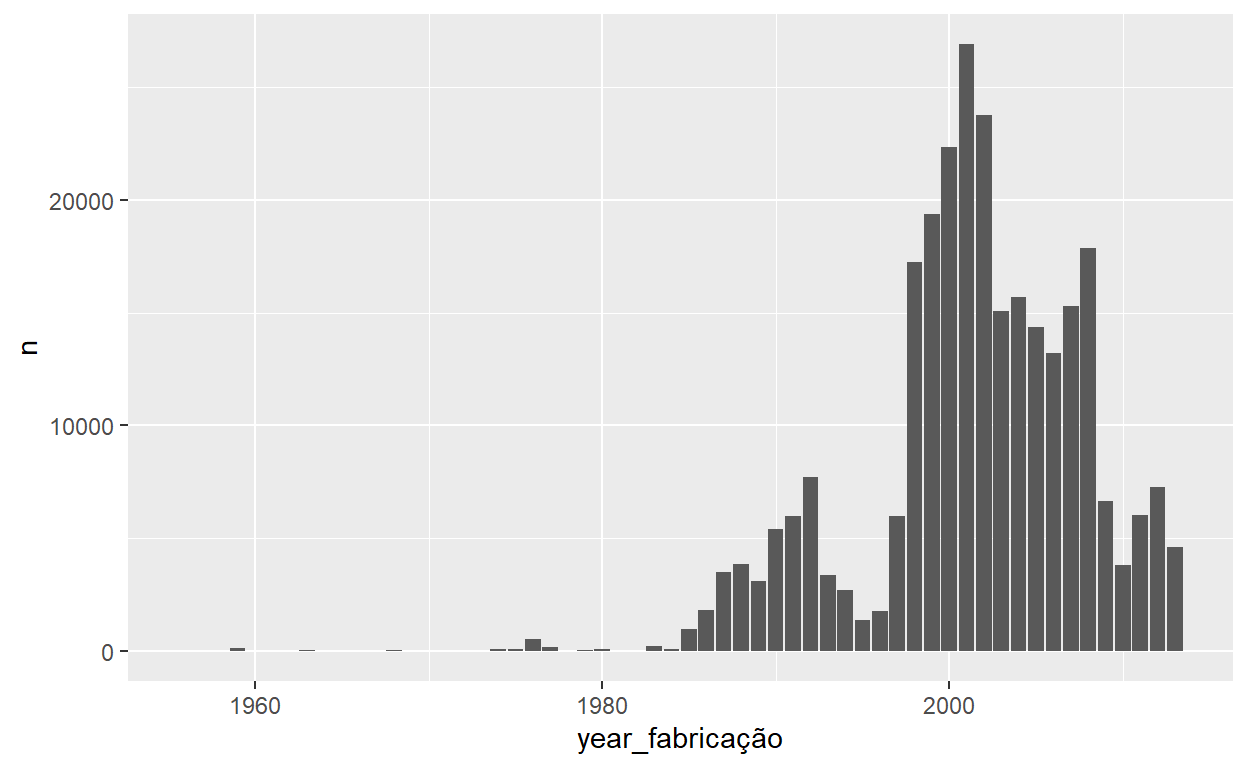
Espero que você não estava nos voos com avião da década 50…
Identificando Observações Faltantes
Até agora, assumimos que os dois bancos contém dados completos: que cada avião que existe no banco de dados flights existe no banco de dados planes (não estamos faltando dados), e que cada avião no banco de dados planes existe no banco de dados flights (não temos aviões que existem mas não voaram). Entender se isso é verdade é importante para verificar se a junção deu certo.
A função útil para identificar as observações que existem em um banco mas não no outro se chama anti_join. Ela segue exatamente o mesmo padrão que left_join(), mas o resultado não é um tibble combinado, é as observações do primeiro tibble que não aparecem no segundo.
flights %>% anti_join(planes, by="tailnum")
Observe que temos 52,606 observações em flights (a tabela acima se imprime os primeiros 10,000) que têm um tailnum que não existe em planes. Isso afeta, por exemplo, o nosso gráfico por ano de fabricação do voo, que falta estes voos. Pode ser crucial entender este viés para a sua análise.
Também é fácil availiar o inverso: se existam aviões que não voaram da Nova Iorque em 2013, invertindo os dois bancos de dados no anti_join().
planes %>% anti_join(flights, by="tailnum")
Boa notícia: todas as aviões de planes são presentes em flights.
Exercício 1: Juntando dois bancos
- Crie dois tibbles pequenos (com a função
tibble()) como eles abaixo e juntar eles pela colunaID.
Mostrar Código
t_combined <- t1 %>%
left_join(t2, by = "ID")
- Execute um join dos bancos de dados
flightseplanespara apenas os voos decarrierUnited (UA) no dia 16 de setembro de 2013. Qual é o modelo (model) de avião mais comum destes voos?
- Quantos assentos (
seats) totais foram instalados nos voos de JFK para Atlanta (ATL) em cada mês?
- Queremos um resumo do número de voos no ano de 2013 por companhia aérea. Mas o nosso banco de
flightsnão contém o nome oficial das companhias. Execute um join entre os banco de dadosflightseairlinespara criar uma tabela resumida e clara.
Juntando Bancos por Múltiplas Variáveis
Considere um outro banco de dados no pacote nycflights13, weather, que contém as condições climáticas em cada aeroporto por hora. Como sabemos o tempo para cada voo? Não é suficiente juntar por origin, obviamente porque o tempo varia por dia e hora e queremos as condições relevantes na hora da partida do voo. Então é necessário realizar a junção com as variáveis que identificam a unidade de análise comum entre os dois bancos: localização e hora.
Localização é fácil: origin existe nos dois bancos. Hora é mais complexo: para definir o momento exato temos que considerar year, month, day e hour. Idealmente queremos incluir ‘minute’ também que existe no banco flights, mas está faltando no banco de weather, então não é possível. Para incluir todas essas variáveis como identificadores comuns, é só incluir eles no argumento do left_join, usando um vector (c()) para designar todas as variáveis relevantes:
Como fica o resultado? Ele tem o mesmo número de linhas que flights e mais dez colunas para as condições clímaticas na hora e local correspondente.
Por interesse, podemos identificar os voos sujeitos à maior velocidade de vento:
O que acontece se esquecemos de um identificador comum relevante? Por exemplo, sem origin?
Opa, o nosso banco agora tem mais de uma milhão de linhas! Por que? Lembre-se que com um left_join começamos com o banco na esquerda e, para cada voo, buscamos as linhas no segundo banco (weather) com o mesmo year, month, day e hour. Por exemplo, o primeiro voo no banco de dados flights partiu na hora:
Quantas observações no banco de dados de weather batem com estes critérios? Vamos ver:
weather %>% filter(year==2013 & month==1 & day==1 & hour==5)
Três. Uma para cada aeroporto de origem, que esquecemos de incluir como identificador comum. Então quando pedimos para R juntar os dois bancos apenas pelas variáveis de year, month, day e hour, adicionamos três observações de tempo para cada voo, triplicando o tamanho do banco de dados resultante. O resultado é que cada voo aparece três vezes, cada um com dados diferentes de tempo, como mostrado na tabela abaixo. Duas das linhas são erradas porque são os dados de tempo de locais diferentes do aeroporto de partida.
A conclusão é simples: sempre inclua todas as variáveis que são identificadores comuns nos dois bancos de dados. Se a left_join() aumenta o número de linhas entre o seu primeiro banco e o resultado, isto significa que existe mais de uma observação no segundo banco com os mesmos valores de variáveis identificadores. É possível que você deseja este resultado, mas é incomum, então presta atenção.
Bancos e Dados Faltantes (right_join, inner_join, full_join, anti_join)
A característica mais importante da função left_join() é que ela tenta ao máximo possível preservar a unidade de análise e número de linhas do primeiro banco na esquerda (left) da junção (o banco que encaminhamos antes do pipe). Assim, não podemos ‘perder’ observações por causa da junção, e se especificamos os identificadores comuns corretamente, não devemos acrescentar observações também.
Porém, o resultado é um banco de dados com dados faltantes - NA - para cada observação que não teve um par no segundo banco de dados. Por exemplo, flights_com_planes cruzou os dados de voos com aqueles dos aviões, mas alguns valores de tailnum no banco de dados de flights não existiam no banco de dados planes. Por exemplo, veja quentos aviões não são conhecidos entre LGA e ORD:
Que tal se quisemos um banco de dados mais ‘limpo’ no resultado da junção dos dois tibbles, tirando as observações que não tem um par no outro banco? Às vezes é útil e eficiente usar a função alternativa inner_join(). Ela funciona identicalmente que left_join() exceto que o resultado falta as observações para quais o identificador comum não existe nos dois bancos:
flights %>% inner_join(planes, by=c("tailnum"))
Quantas observações existem no resultado? 284170, a diferença entre o número de observações em flights (336776) e os voos sem tailnum em planes, o resultado de anti_join que executamos acima (52606). É uma boa exercício verificar.
Frequentemente, usando um inner_join gera um viés de seleção - não sabemos muito sobre as aviões faltandas, mas não podemos ignorar eles para uma análise quantitativa. Então sempre recomendamos um left_join() como a ferramenta padrão.
Para mostrar situações mais complexas, vamos trabalhar com um outro banco de dados do pacote nycflights13, os dados de airports, que contém o seu nome completo, localização etc. O primeiro desafio aqui é que temos que decidir como a juntar os bancos? No flights temos duas colunas sobre aeroportos: origin e dest. Lembrando que origin é só os três aeroportos de Nova Iorque, juntando por origin vai gerar muita repetição. Então vamos importar os dados do aeroporto do destino, dest.
O identificador único do tibble airports é faa, que usa o mesmo código official que dest, que é ótimo. Porém, os nomes de colunas são diferentes nos dois bancos: dest e faa. Como resolvemos a diferença? Há várias possibilidades, mas sugerimos renomear a coluna de um banco antes de executar a junção para evitar problemas. Dado que as variáveis refletem exatamente o mesmo conteúdo, faz sentido que eles teriam nome ígual:
Outro ponto para reconhecer é que estamos adicionando muitas novas colunas de airports ao flights que pode poluir a nossa análise/apresentação. As vezes é melhor selecionar as colunas de interesse no segundo banco antes de realizar a junção. Por exemplo, se apenas quisemos o nome completo do aeroporto:
Voltando a questão de dados faltantes, há mais uma maneira em que os airports são difíceis para juntar: Em contraste com os dados de planes, airports inclui aeroportos que não foram destinos dos voos de flights. Então ambos os anti_joins mostram observações faltantes:
Lembre-se que o nosso left_join preservou todos os dados de flights e incorporou (como colunas novas) os dados de apenas os aeroportos que são presentes na coluna dest. Ou seja, o left em left_join preserva os dados do tibble na esquerda (o primeiro tibble no código).
Não precisa ser assim: existe também um right_join que preserva os dados do tibble na direita, incluindo todas as observações da direita e apenas eles da esquerda que tem um par na direita. Com o nosso exemplo de flights e airports:
flights %>% right_join(airports, by=c("dest"))
Veja que o número de observações diminuiu para 330,531, porque tiramos os voos de flights para as quais não tem dados sobre aeroportos.
Preservando as observações de airports com right_join() também significa que qualquer aeroporto sem voo aparece no resultado, mas com muitos NA para as colunas que pertencem aos dados de flights que faltamos. São os aeroportos que não foram destinos dos voos da Nova Iorque, por exemple ‘04G’, ‘Lansdowne Airport’:
flights %>% right_join(airports, by=c("dest")) %>%
filter(is.na(year)) %>%
select(year, month, day, flight, dest, name)
Uma dica: na maioria de situações, é mais fácil trabalhar com left_join() para evitar confusão.
Finalmente, é possível realizar um tipo de junção que preserva as observações de ambos os bancos de dados. Isto sempre vai gerar o maior banco de dados possível, pois mantemos todas as observações do primeiro banco de dados, e também todas do segundo banco, mesmo se eles nào tenham par no outro banco. A função se chama full_join()
Quantas observações agora? 338,133, acima de 336,776 no flights pela quantidade de aeroportos faltando em flights, 1,357 (da anti_join acima).
Resumindo, existem cinco tipos de joins que produzem resultados differentes:
| Tipo | Resultado |
|---|---|
| left_join | Preservando todas as observações de Banco 1 com as colunas adicionais de Banco 2 |
| right_join | Preservando todas as observações de Banco 2 com as colunas adicionais de Banco 1 |
| inner_join | Preservando apenas as observações presentes em ambos os Bancos |
| full_join | Preservando todas as observações dos dois bancos |
| anti_join | Identificar as observações em Banco 1 ausentes em Banco 2 |
Exercício 2: Joins com Dados Faltantes
- Crie dois tibbles pequenos (com a função
tibble()) como eles abaixo e juntar eles pelos identificadores comuns usandoleft_join().
- Queremos dois banco de dados:
- Um limpo que contém apenas as observações com dados completos para ambos valor e população. Use um join apropriado, e o identificador comum, para criar este banco de dados.
Mostrar Código
t1 %>%
inner_join(t2, by = c("ID", "Ano"))
- Um ‘completo’ que contém todas as observações mesmo que não existe par no outro banco. Use um join apropriado, e o identificador comum, para criar este banco de dados.
- Usando os banco de dados
flightseweather, identifique a precipitatação (precip) média no momento de partido dos voos de LGA em cada dia de dezembro.
- Usando os banco de dados
- Para quantos voos em cada dia de dezembro em LGA faltamos dados de tempo?
- Para quantos horas em cada dia de dezembro em LGA temos dados sobre o tempo mas não temos nenhum voo?
- Agora vamos investigar se a visibilidade afeta o número de partidas por hora.
- Usando um join apropriado, gere um banco de dados que inclui a
visibilidadeem cada hora do ano e o número de voos que decolaram nesta hora.
- Resuma o seu banco de dados criado em (4a) para estimar a média do número de voos por hora por valor da variável
visibilidade. Mostre os resultados num gráfico de pontos.
Nesting data (nest, unnest)
Agora vamos mudar direção e discutir um tópico menos ‘essencial’ mas bastante intuitivo e pedagógico que deve te ajudar entender e organizar os seus dados. Até agora, vejamos dois jeitos de ‘agrupar’ dados parecidos: (i) com variáveis discretas/categórica e o uso de group_by() para definir o escopo da transformação/resumo de dados, e (ii) em tibbles diferentes (como flights e airports, usando left_join para juntar os dados).
Existe uma terceira opção que fica no meio do caminho entre os dois: Podemos colocar tibbles separados dentro de um tibble ‘superior’, e identificar o conteúdo de cada mini-tibble com uma variável discreta. Um pouco estranho, mas fará muito sentido em breve. O mais fácil é ver um exemplo do processo que se chama nesting.
flights_nested <- flights %>% group_by(origin) %>%
nest()
A lógica do código é usar a mesma linguagem de agrupamento, group_by(), para agrupar por aeroporto de origem, e depois usar a função nest() (sem argumentos) para ‘colapsar’ o resto do tibble por aeroporto de origem na coluna de data. Isso gera um mini-tibble novo para cada aeroporto, que fica na linha apropriada e identificada pela coluna origin no novo tibble.
Para acessar os dados apenas de ‘EWR’ agora, é só filtrar para a coluna e linha apropriada e vejamos que é uma tabela inteira:
flights_nested %>% filter(origin=="EWR") %>%
pull(data)
flights_nested
Nesting é ainda mais útil com mais variáveis de agrupamento:
flights_nested <- flights %>% group_by(origin, carrier) %>%
nest() %>%
arrange(carrier, origin)
flights_nested
Agora temos um tibble com 35 observações em que a unidade de análise é cada companhia aérea em cada aeroporto, e a coluna ‘data’ contém um tibble dos voos da companhia aérea e aeroporto de origem correspondente. Para voltar ao tibble original, é só aplicar unnest.
flights_nested %>% unnest()
Por que o ‘nesting’ é valioso? Todas as operações de programação podem ser feitos sem nesting, mas o valor é deixar mais claro a estrutura e o conteúdo dos nossos dados. Podemos trabalhar explicitamente com a unidade de análise relevante, e esconder a montanha de dados internos. No futuro vamos aprender como a aplicar funções para cada tibble na coluna de ‘data’, que facilita também a repetição de funções complexas por grupo.
Mais um exemplo, combinando nest com left_join, deixando claro que a unidade de análise é cada avião, evitando a duplicação dos dados dos aviões para cada linha, e colapsando as viagens de cada avião na sua própria mini-tibble numa coluna dedicada:
Exercício 3: Dados Nested
- Crie um tibble nested em que a unidade de análise é cada combinação de origem e destino, e numa outra coluna em mini-tibbles ficam todos os detalhes dos voos entre aquele origem e destino.
Mostrar Código
flights %>%
group_by(origin, dest) %>%
nest()
- Crie um tibble nested que resume o banco de dados
flightspor aeroporto de origem, mês, dia e hora. Use um join para juntar os dados deweatherpara cada aeroporto e hora.
Leitura para Tutorial 8
Antes da próxima aula, por favor leia Exemplo de Análise Espacial no Site R-Spatial
Desafio 3
O Desafio 3 teste a sua capacidade de juntar bancos de dados e gerar gráficos apropriados e claros.
O prazo para entregar Desafio 3 por email com título “[FLS6397] - D3” à minha conta é 14h, 04/06/2021, antes da aula. Por favor entregue (i) o arquivo .Rmd, e (ii) o arquivo .html.